admin12个月前5101
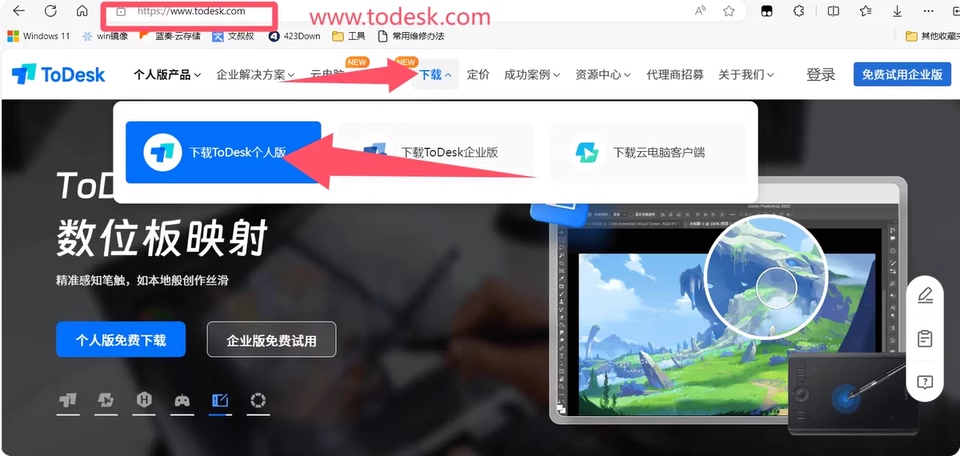
猫行云一键重装系统-装机助理 下载1 todesk远程 下载1 只要20-40分钟快速重装。根据用户网速。第一步:下载todesk.com远程,拍设备代码(数字与密码)给...
admin12个月前4105
猫行云PE维护系统_网络版-下载1todesk远程下载只要20-40分钟快速重装。根据用户网速。第一步:下载todesk.com远程,拍设备代码(数字与密码)给我。客服微信...
admin12个月前3517
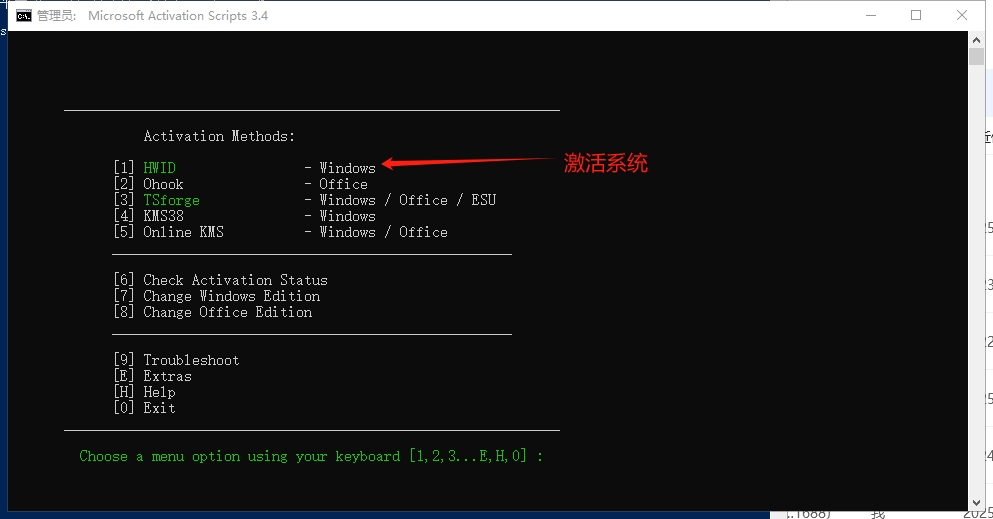
官理员运行命令irm https://get.activated.win | iex...
admin11个月前2548
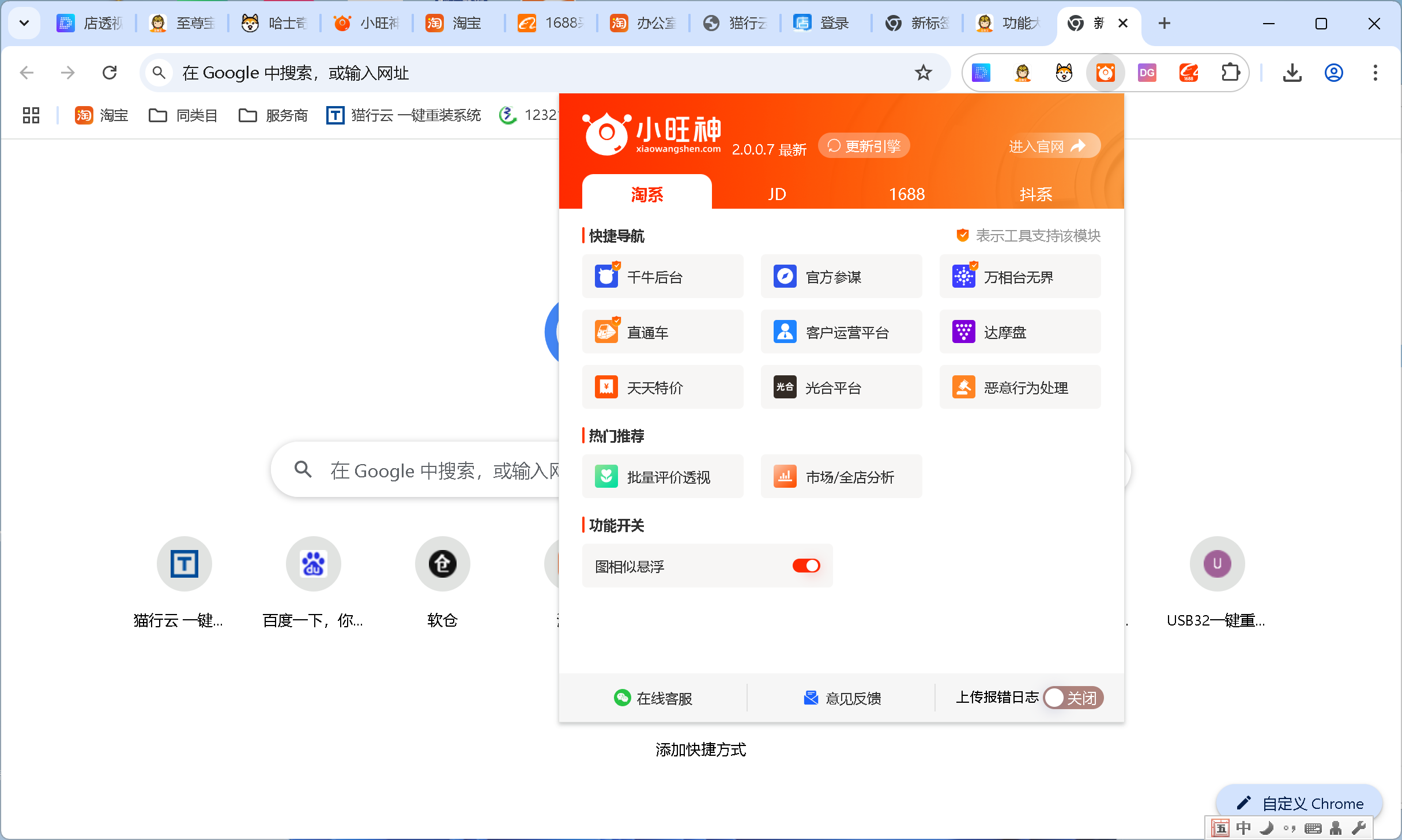
diantoushi.com 店透视https://zzbtool.com/index.html 至尊宝https://hsq.dangxun.com/哈士奇...
admin11个月前1953
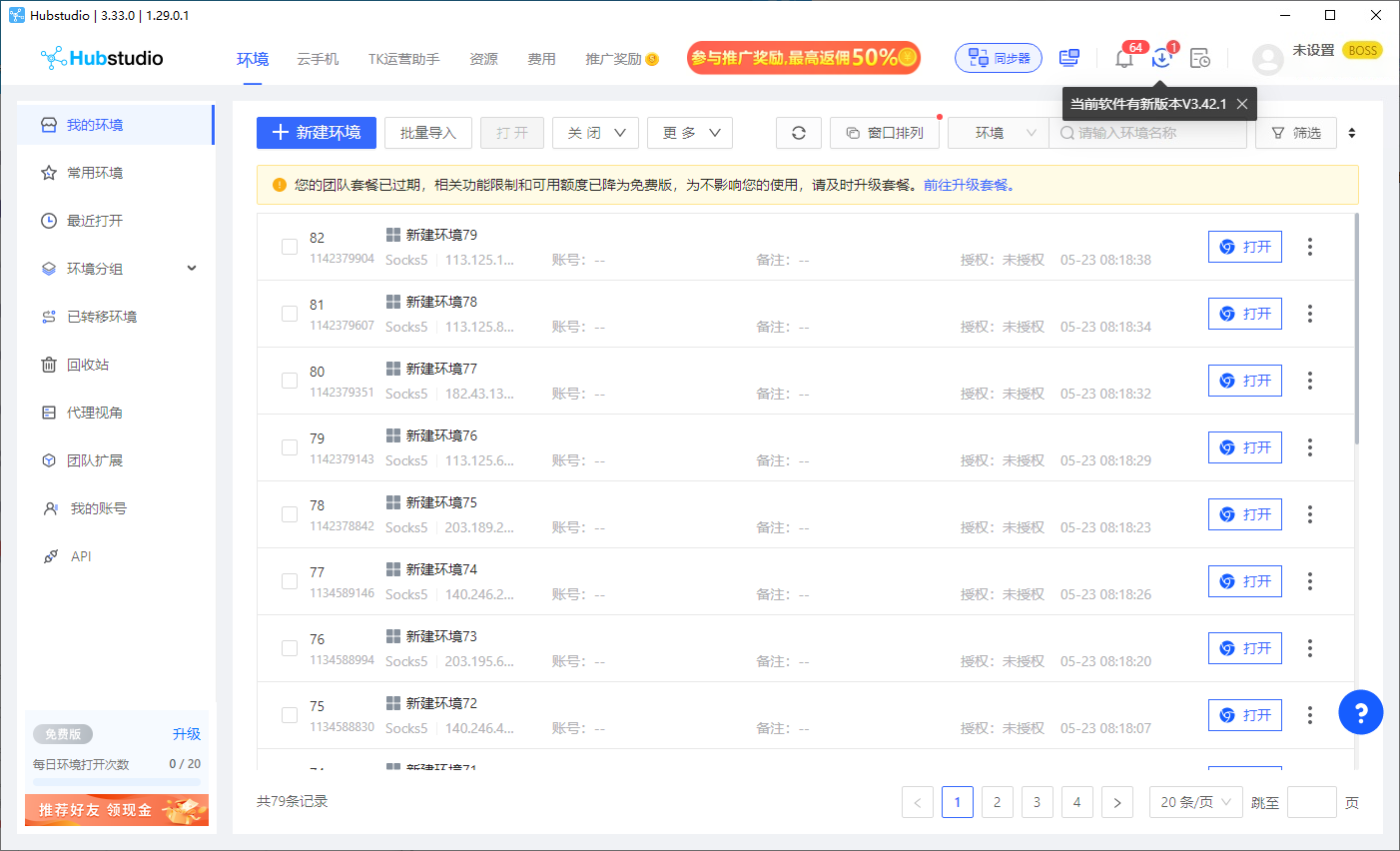
猫行云亲测十几款指纹浏览器,最终选择了,Hubstudio 提供的专业出海多账号环境。不仅有免费不限量的指纹浏览器环境,还有专注TK媲美真机的云手机环境。我身边的跨境人都在用,...